ENG | Recovering GPS tracks from old MyTourBook database
Success story of reverse-engineering and data recovery from Apache Derby database

MyTourBook is a desktop application used to manage and analyze GPS-based activity data such as bike rides and hikes. I used it between 2008 and 2012 to record my activities, and recently discovered a backup of its data files. Since I no longer use MyTourBook, I wanted to recover this data and migrate it to modern platforms like Strava or Garmin Connect. I still have some assorted GPX tracks from this years, but I assume these data is better organized as I’ve put some effort into importing them, tagging them and cropping start/finish.
By that time, bike, geocaching, exploration and putting tracks into OpenStreetMaps were my hobbies, Garmin Vista HCx GPS was a nice, wanted birthday gift.
At start, I knew nothing about how application stores it’s data. I identified it’s Java application using Apache Derby database.
This post documents the process of reverse engineering, data recovery and setting environment for it.
For reader it assumes familiarity with Python, little bit of SQL and data recovery tools (which I’m lacking) and it’s not for everyone.
ChatGPT and Claude.AI helped me a lot with this as I’m not familiar with all Python libraries and whole recovery process took me roughly one day.
Database recovery
Installing Apache derby
Check if Java is installed, which hopefully is on my Linux system.
1
java --version
1
2
3
openjdk 21.0.7 2025-04-15
OpenJDK Runtime Environment (Red_Hat-21.0.7.0.6-1) (build 21.0.7+6)
OpenJDK 64-Bit Server VM (Red_Hat-21.0.7.0.6-1) (build 21.0.7+6, mixed mode, sharing)
Download Apache Derby database
1
2
3
4
cd Downloads
wget https://dlcdn.apache.org//db/derby/db-derby-10.17.1.0/db-derby-10.17.1.0-bin.zip
cd ..
unzip ~/Downloads/db-derby-10.17.1.0-bin.zip
Prepare environment and try it
1
2
3
export DERBY_HOME=/home/pavel/db-derby-10.17.1.0-bin
export CLASSPATH=$DERBY_HOME/lib/derby.jar:$DERBY_HOME/lib/derbytools.jar:$CLASSPATH
java -jar $DERBY_HOME/lib/derbyrun.jar ij
1
2
ij version 10.17
ij>
Copying MyTourBook database to Linux machine
Unpack backup of MyTourBook data (copied to ~/tmp)
1
2
cd tmp
7z x c_users_pavel_mytourbook_20120128_v9_08.7z
Exploring the database structure
Few examples of useful SQL commands
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
ij> show schemas;
TABLE_SCHEM
------------------------------
APP
NULLID
SQLJ
SYS
SYSCAT
SYSCS_DIAG
SYSCS_UTIL
SYSFUN
SYSIBM
SYSPROC
SYSSTAT
USER
12 rows selected
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
ij> show tables in USER;
TABLE_SCHEM |TABLE_NAME |REMARKS
------------------------------------------------------------------------
USER |DBVERSION |
USER |TOURBIKE |
USER |TOURCATEGORY |
USER |TOURCATEGORY_TOURDATA |
USER |TOURCOMPARED |
USER |TOURDATA |
USER |TOURDATA_TOURMARKER |
USER |TOURDATA_TOURREFERENCE |
USER |TOURDATA_TOURTAG |
USER |TOURMARKER |
USER |TOURPERSON |
USER |TOURREFERENCE |
USER |TOURTAG |
USER |TOURTAGCATEGORY |
USER |TOURTAGCATEGORY_TOURTAG |
USER |TOURTAGCATEGORY_TOURTAGCATEGO&|
USER |TOURTYPE |
17 rows selected
1
2
3
4
5
6
7
8
9
10
11
ij> describe USER.TOURBIKE;
COLUMN_NAME |TYPE_NAME|DEC&|NUM&|COLUM&|COLUMN_DEF|CHAR_OCTE&|IS_NULL&
------------------------------------------------------------------------------
BIKEID |BIGINT |0 |10 |19 |AUTOINCRE&|NULL |NO
NAME |VARCHAR |NULL|NULL|255 |NULL |510 |YES
WEIGHT |DOUBLE |NULL|2 |52 |NULL |NULL |YES
TYPEID |INTEGER |0 |10 |10 |NULL |NULL |YES
FRONTTYREID |INTEGER |0 |10 |10 |NULL |NULL |YES
REARTYREID |INTEGER |0 |10 |10 |NULL |NULL |YES
6 rows selected
Note that USER is reserved keyword and it must be put into quotes.
1
2
3
4
5
6
ij> select * from "USER".DBVERSION;
VERSION
-----------
7
1 row selected
Exporting database tables
Here I asked Claude.AI to export database into CSV files and it gave me nice python script. Dump to SQL statements is completely unnecessary and kept only because script works and I didn’t want to break it.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
import jaydebeapi
import pandas as pd
import os
# Path to your Derby database
db_path = "/home/pavel/tmp/mytourbook/derby-database/tourbook"
# Connect to Derby
conn = jaydebeapi.connect(
"org.apache.derby.jdbc.EmbeddedDriver",
f"jdbc:derby:{db_path}",
[],
"/path/to/derby/lib/derby.jar"
)
cursor = conn.cursor()
# Get all schemas
cursor.execute("SELECT SCHEMANAME FROM SYS.SYSSCHEMAS")
schemas = [row[0] for row in cursor.fetchall()]
print(f"Found schemas: {schemas}")
# Create output directory
os.makedirs("derby_export", exist_ok=True)
# For each schema, get tables and dump data
for schema in schemas:
if schema in ('SYS', 'SYSIBM', 'SYSCS_DIAG', 'SYSCS_UTIL', 'SYSFUN'):
continue # Skip system schemas
cursor.execute(f"SELECT TABLENAME FROM SYS.SYSTABLES WHERE SCHEMAID IN (SELECT SCHEMAID FROM SYS.SYSSCHEMAS WHERE SCHEMANAME = '{schema}')")
tables = [row[0] for row in cursor.fetchall()]
print(f"Found tables in {schema}: {tables}")
# Export each table
for table in tables:
print(f"Exporting {schema}.{table}")
try:
# Read to pandas DataFrame
df = pd.read_sql(f'SELECT * FROM "{schema}"."{table}"', conn)
# Save as CSV
df.to_csv(f"derby_export/{schema}_{table}.csv", index=False)
# Generate SQL INSERT statements
with open(f"derby_export/{schema}_{table}.sql", 'w') as f:
# Write CREATE TABLE statement (simplified)
cursor.execute(f"SELECT COLUMNNAME, COLUMNDATATYPE FROM SYS.SYSCOLUMNS C JOIN SYS.SYSTABLES T ON C.REFERENCEID = T.TABLEID WHERE T.TABLENAME = '{table}' AND T.SCHEMAID IN (SELECT SCHEMAID FROM SYS.SYSSCHEMAS WHERE SCHEMANAME = '{schema}')")
columns = cursor.fetchall()
create_stmt = f"CREATE TABLE {schema}.{table} (\n"
create_stmt += ",\n".join([f" {col[0]} {col[1]}" for col in columns])
create_stmt += "\n);\n\n"
f.write(create_stmt)
# Write INSERT statements
for _, row in df.iterrows():
values = []
for item in row:
if pd.isna(item):
values.append("NULL")
elif isinstance(item, str):
values.append(f"'{item.replace("'", "''")}'")
else:
values.append(str(item))
f.write(f"INSERT INTO {schema}.{table} VALUES ({', '.join(values)});\n")
except Exception as e:
print(f"Error exporting {schema}.{table}: {e}")
cursor.close()
conn.close()
print("Export complete!")
File listing of exported tables looks quite sad:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
total 252
drwxr-xr-x. 1 pavel pavel 1588 Apr 30 17:21 .
drwx------. 1 pavel pavel 330 Apr 30 17:21 ..
-rw-r--r--. 1 pavel pavel 10 Apr 30 17:21 USER_DBVERSION.csv
-rw-r--r--. 1 pavel pavel 100 Apr 30 17:21 USER_DBVERSION.sql
-rw-r--r--. 1 pavel pavel 49 Apr 30 17:21 USER_TOURBIKE.csv
-rw-r--r--. 1 pavel pavel 159 Apr 30 17:21 USER_TOURBIKE.sql
-rw-r--r--. 1 pavel pavel 35 Apr 30 17:21 USER_TOURCATEGORY.csv
-rw-r--r--. 1 pavel pavel 116 Apr 30 17:21 USER_TOURCATEGORY.sql
-rw-r--r--. 1 pavel pavel 40 Apr 30 17:21 USER_TOURCATEGORY_TOURDATA.csv
-rw-r--r--. 1 pavel pavel 123 Apr 30 17:21 USER_TOURCATEGORY_TOURDATA.sql
-rw-r--r--. 1 pavel pavel 77 Apr 30 17:21 USER_TOURCOMPARED.csv
-rw-r--r--. 1 pavel pavel 239 Apr 30 17:21 USER_TOURCOMPARED.sql
-rw-r--r--. 1 pavel pavel 44412 Apr 30 17:21 USER_TOURDATA.csv
-rw-r--r--. 1 pavel pavel 63601 Apr 30 17:21 USER_TOURDATA.sql
-rw-r--r--. 1 pavel pavel 36 Apr 30 17:21 USER_TOURDATA_TOURMARKER.csv
-rw-r--r--. 1 pavel pavel 117 Apr 30 17:21 USER_TOURDATA_TOURMARKER.sql
-rw-r--r--. 1 pavel pavel 36 Apr 30 17:21 USER_TOURDATA_TOURREFERENCE.csv
-rw-r--r--. 1 pavel pavel 120 Apr 30 17:21 USER_TOURDATA_TOURREFERENCE.sql
-rw-r--r--. 1 pavel pavel 891 Apr 30 17:21 USER_TOURDATA_TOURTAG.csv
-rw-r--r--. 1 pavel pavel 3084 Apr 30 17:21 USER_TOURDATA_TOURTAG.sql
-rw-r--r--. 1 pavel pavel 7658 Apr 30 17:21 USER_TOURMARKER.csv
-rw-r--r--. 1 pavel pavel 14881 Apr 30 17:21 USER_TOURMARKER.sql
-rw-r--r--. 1 pavel pavel 173 Apr 30 17:21 USER_TOURPERSON.csv
-rw-r--r--. 1 pavel pavel 375 Apr 30 17:21 USER_TOURPERSON.sql
-rw-r--r--. 1 pavel pavel 95 Apr 30 17:21 USER_TOURREFERENCE.csv
-rw-r--r--. 1 pavel pavel 263 Apr 30 17:21 USER_TOURREFERENCE.sql
-rw-r--r--. 1 pavel pavel 73 Apr 30 17:21 USER_TOURTAGCATEGORY.csv
-rw-r--r--. 1 pavel pavel 346 Apr 30 17:21 USER_TOURTAGCATEGORY.sql
-rw-r--r--. 1 pavel pavel 62 Apr 30 17:21 USER_TOURTAGCATEGORY_TOURTAGCATEGORY.csv
-rw-r--r--. 1 pavel pavel 155 Apr 30 17:21 USER_TOURTAGCATEGORY_TOURTAGCATEGORY.sql
-rw-r--r--. 1 pavel pavel 44 Apr 30 17:21 USER_TOURTAGCATEGORY_TOURTAG.csv
-rw-r--r--. 1 pavel pavel 129 Apr 30 17:21 USER_TOURTAGCATEGORY_TOURTAG.sql
-rw-r--r--. 1 pavel pavel 84 Apr 30 17:21 USER_TOURTAG.csv
-rw-r--r--. 1 pavel pavel 332 Apr 30 17:21 USER_TOURTAG.sql
-rw-r--r--. 1 pavel pavel 405 Apr 30 17:21 USER_TOURTYPE.csv
-rw-r--r--. 1 pavel pavel 949 Apr 30 17:21 USER_TOURTYPE.sql
Fuck!
There are only a few tables containing actual data and none of them is particularly large. USER.TOURDATA looks like this:
TOURID,STARTYEAR,STARTMONTH,STARTDAY,STARTHOUR,STARTMINUTE,STARTWEEK,STARTDISTANCE,DISTANCE,STARTALTITUDE,STARTPULSE,DPTOLERANCE,TOURDISTANCE,TOURRECORDINGTIME,TOURDRIVINGTIME,TOURALTUP,TOURALTDOWN,DEVICETOURTYPE,DEVICETRAVELTIME,DEVICEDISTANCE,DEVICEWHEEL,DEVICEWEIGHT,DEVICETOTALUP,DEVICETOTALDOWN,DEVICEPLUGINID,DEVICEMODE,DEVICETIMEINTERVAL,MAXALTITUDE,MAXPULSE,AVGPULSE,AVGCADENCE,AVGTEMPERATURE,MAXSPEED,TOURTITLE,TOURDESCRIPTION,TOURSTARTPLACE,TOURENDPLACE,CALORIES,BIKERWEIGHT,TOURBIKE_BIKEID,DEVICEPLUGINNAME,DEVICEMODENAME,TOURTYPE_TYPEID,TOURPERSON_PERSONID,TOURIMPORTFILEPATH,MERGESOURCETOURID,MERGETARGETTOURID,MERGEDTOURTIMEOFFSET,MERGEDALTITUDEOFFSET,STARTSECOND,SERIEDATA
2008821994677,2008,8,2,19,9,31,0,0,0,0,50,4677,8157,7671,138,138,,0,0,0,0,0,0,net.tourbook.device.GarminDeviceReader,0,-1,551,0,0,0,0,7.5,Sofia,,,,,65.0,,GPX,,3.0,0,D:\foto\2008\bulharsko\gps-stats\2008-08-02-Sofia.gpx,,,0,0,1,org.apache.derby.impl.jdbc.EmbedBlob@15dcfae7
Or formatted
| Field | Value |
|---|---|
| TOURID | 2008721134510213 |
| STARTYEAR | 2008 |
| STARTMONTH | 7 |
| STARTDAY | 21 |
| STARTHOUR | 13 |
| STARTMINUTE | 45 |
| STARTWEEK | 30 |
| STARTDISTANCE | 0 |
| DISTANCE | 0 |
| STARTALTITUDE | 0 |
| STARTPULSE | 0 |
| DPTOLERANCE | 50 |
| TOURDISTANCE | 10213 |
| TOURRECORDINGTIME | 21477 |
| TOURDRIVINGTIME | 16590 |
| TOURALTUP | 1102 |
| TOURALTDOWN | 47 |
| DEVICETOURTYPE | (empty) |
| DEVICETRAVELTIME | 0 |
| DEVICEDISTANCE | 0 |
| DEVICEWHEEL | 0 |
| DEVICEWEIGHT | 0 |
| DEVICETOTALUP | 0 |
| DEVICETOTALDOWN | 0 |
| DEVICEPLUGINID | net.tourbook.device.GarminDeviceReader |
| DEVICEMODE | 0 |
| DEVICETIMEINTERVAL | -1 |
| MAXALTITUDE | 2392 |
| MAXPULSE | 0 |
| AVGPULSE | 0 |
| AVGCADENCE | 0 |
| AVGTEMPERATURE | 0 |
| MAXSPEED | 15.0 |
| TOURTITLE | Borovetz - Musala (chata) |
| TOURDESCRIPTION | (empty) |
| TOURSTARTPLACE | (empty) |
| TOURENDPLACE | (empty) |
| CALORIES | (empty) |
| BIKERWEIGHT | 65.0 |
| TOURBIKE_BIKEID | (empty) |
| DEVICEPLUGINNAME | GPX |
| DEVICEMODENAME | (empty) |
| TOURTYPE_TYPEID | 3.0 |
| TOURPERSON_PERSONID | 0 |
| TOURIMPORTFILEPATH | D:\foto\2008\bulharsko\gps-stats\2008-07-21-Borovec-chMusala.gpx |
| MERGESOURCETOURID | (empty) |
| MERGETARGETTOURID | (empty) |
| MERGEDTOURTIMEOFFSET | 0 |
| MERGEDALTITUDEOFFSET | 0 |
| STARTSECOND | 43 |
| SERIEDATA | org.apache.derby.impl.jdbc.EmbedBlob@3da05287 |
Wait. So at the end, there’s SERIEDATA entry with value org.apache.derby.impl.jdbc.EmbedBlob@3da05287. So there are binary objects (BLOB=Binary large object)
Exporting BLOBs (binary objects)
Now I asked chatgpt to generate script for extrating blobs from this table. This is code after like 4 iterations of fixing bugs:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
import jaydebeapi
import os
import jpype
# Config
derby_home = "/home/pavel/tmp/mytourbook/"
output_dir = "derby_export/blobs"
# Ensure export directory exists
os.makedirs(output_dir, exist_ok=True)
# Connect to Derby
db_path = "/home/pavel/tmp/mytourbook/derby-database/tourbook"
# Connect to Derby
conn = jaydebeapi.connect(
"org.apache.derby.jdbc.EmbeddedDriver",
f"jdbc:derby:{db_path}",
[],
"/path/to/derby/lib/derby.jar"
)
conn.jconn.setAutoCommit(False)
curs = conn.cursor()
# Select TOURID and BLOB data
query = 'SELECT "TOURID", "SERIEDATA" FROM "USER"."TOURDATA"'
curs.execute(query)
for tourid, blob in curs.fetchall():
filename = f"{output_dir}/USER_TOURDATA_SERIEDATA_{tourid}.bin"
length = blob.length()
#data = blob.getBytes(1, length) # position is 1-based in JDBC
data = blob.getBytes(jpype.JLong(1), int(length))
with open(filename, "wb") as f:
f.write(data)
# Clean up
conn.jconn.commit()
curs.close()
conn.close()
Blob is sadly binary file of unknown structure. I found relatively small GPS track from Sofia, which looks like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
<?xml version="1.0" encoding="UTF-8" standalone="no" ?>
<gpx xmlns="http://www.topografix.com/GPX/1/1" creator="MapSource 6.13.7" version="1.1" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.garmin.com/xmlschemas/GpxExtensions/v3 http://www.garmin.com/xmlschemas/GpxExtensions/v3/GpxExtensionsv3.xsd http://www.topografix.com/GPX/1/1 http://www.topografix.com/GPX/1/1/gpx.xsd">
<metadata>
<link href="http://www.garmin.com">
<text>Garmin International</text>
</link>
<time>2008-08-06T11:15:16Z</time>
</metadata>
<trk>
<name>2008-08-02-Sofia</name>
<extensions>
<gpxx:TrackExtension xmlns:gpxx="http://www.garmin.com/xmlschemas/GpxExtensions/v3">
<gpxx:DisplayColor>White</gpxx:DisplayColor>
</gpxx:TrackExtension>
</extensions>
<trkseg>
<trkpt lat="42.7067260" lon="23.3231620">
<ele>536.0180000</ele>
<time>2008-08-02T17:09:01Z</time>
</trkpt>
<trkpt lat="42.7051910" lon="23.3241150">
<ele>533.6940000</ele>
<time>2008-08-02T17:15:00Z</time>
</trkpt>
<trkpt lat="42.7011730" lon="23.3228840">
<ele>421.3160000</ele>
<time>2008-08-02T17:29:25Z</time>
</trkpt>
<trkpt lat="42.7065840" lon="23.3226790">
<ele>535.9800000</ele>
<time>2008-08-02T19:24:58Z</time>
</trkpt>
</trkseg>
</trk>
</gpx>
I compared GPX files with values in BLOB and then two BLOBs side by side in ImHex and after playing it for about an hour I decoded it’s structure, which seems fixed - at least for GPS data which all contain elevation, but no other information such as heartbeat, pedaling cadence, watts or so.
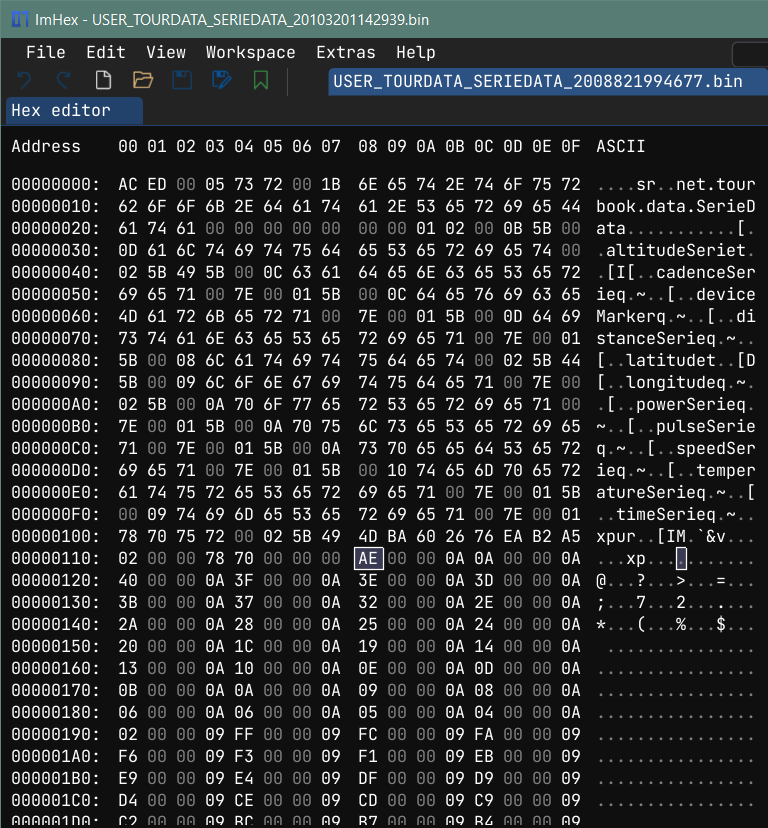
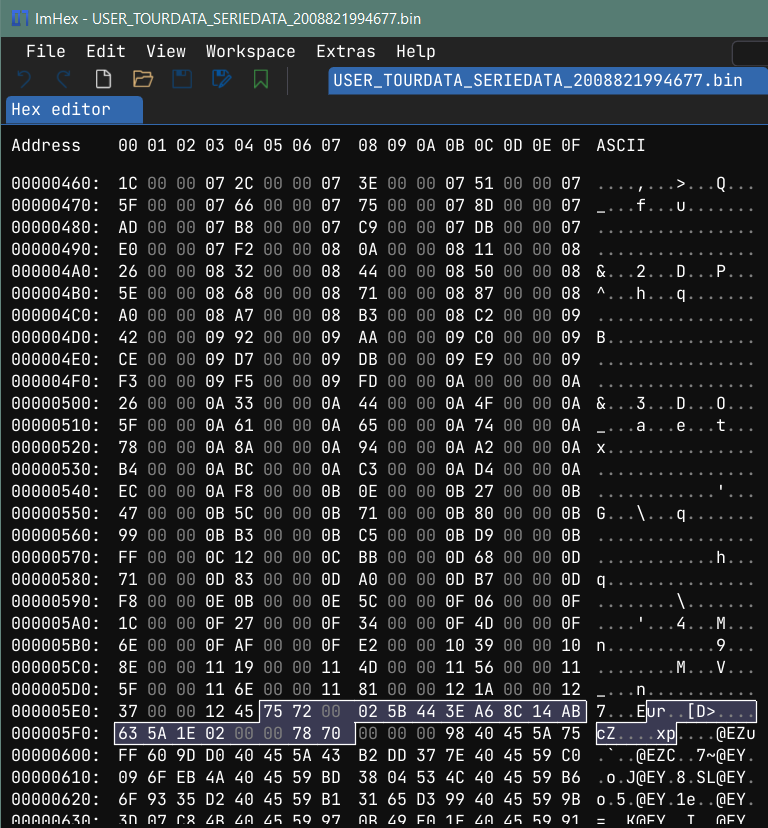
The structure of file is this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Offset 0x0000: some fixed header
Offset 0x0115: number of height points, uint32_t (e.g 0x98 = 152)
Offset 0x0119: first height point in whole meters (int32_t),
e.g 0x0218 = 536, 0x216=534, 0x1A6=422
Offset 0x379: 70 70 75 71 00 7e 00 04: unknown 8 bytes, offset is 0x119+4*0x98
Offset 0x381: 0x00000098
Offset 0x385: 0x00, 0xBB, 0x285 ... 0x1245 (0, 187, 645, .... 4677) Distance in meters from start
Offset 0x5E5: 75 72 00 02 5B 44 3E A6 8C 14 AB 63 5A 1E 02 00 00 78 70 (19 bytes)
Offset 0x5F8: 0x00000098
Offset 0x5FC: 40 45 5A 75 FF 60 9D D0 (42.7067) - latitude
Offset 0xABC: 75 71 00 7e 00 07 (6 bytes)
Offset 0xAC2: 0x00000098
Offset 0xAC6: 40 37 52 BA BE AD 4F 59 (23.3232) - longitude
Offset 0xF86: 70 70 70 70 75 71 00 7E 00 04 (10 bytes)
Offset 0XF90: 0x00000098
Offset 0XF94: 0, 0x167, 0x4c8 (0, 359, 114) - seconds from start
Reconstructing GPX files
Here I wrote mostly my own code for GPX file reconstruction. Code for creating GPX file is again AI generated.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
#! /usr/bin/python
# This file reads USER_TOURDATA.csv and for each entry it decodes
# track title, starting time. It acquires datapoints from exported BLOBs.
# Based on these information GPX file is reconstructed.
import os
import struct
import pandas as pd
import datetime
import pytz
import numpy as np
from datetime import timedelta
import xml.etree.ElementTree as ET
import xml.dom.minidom as minidom
blobs_dir = "derby_export/blobs"
csv_path = "derby_export/USER_TOURDATA.csv"
output_dir = "derby_export/gpx"
local_tz = pytz.timezone('Europe/Prague')
utc_tz = pytz.UTC
def parse_blob(blob_file):
with open(blob_file, 'rb') as f:
data = f.read()
num_points = struct.unpack('>I', data[0x115:0x119])[0]
print(f"Found {num_points} data points")
altitudes_offset = 0x119
distances_offset = altitudes_offset + num_points * 4 + 8 + 4;
latitudes_offset = distances_offset + num_points * 4 + 19 + 4;
longitudes_offset = latitudes_offset + num_points * 8 + 6 + 4;
seconds_offset = longitudes_offset + num_points * 8 + 10 + 4;
expected_file_size = seconds_offset + num_points * 4;
if expected_file_size != len(data):
return
altitudes = np.frombuffer(data, offset=altitudes_offset, dtype=">i4", count=num_points)
distances = np.frombuffer(data, offset=distances_offset, dtype=">i4", count=num_points)
latitudes = np.frombuffer(data, offset=latitudes_offset, dtype='>f8', count=num_points)
longitudes = np.frombuffer(data, offset=longitudes_offset, dtype='>f8', count=num_points)
seconds = np.frombuffer(data, offset=seconds_offset, dtype='>i4', count=num_points)
return {
'num_points': num_points,
'altitudes': altitudes,
'distances': distances,
'latitudes': latitudes,
'longitudes': longitudes,
'seconds': seconds
}
def create_gpx(tour):
print(f"Processing tour {tour.TOURID} ({tour.TOURTITLE})")
blob_file = os.path.join(blobs_dir, f"USER_TOURDATA_SERIEDATA_{tour.TOURID}.bin")
serie_data = parse_blob(blob_file)
if serie_data is None:
print("No serie data")
return
# Get start time
start_time_local = datetime.datetime(
year = int(tour.STARTYEAR),
month = int(tour.STARTMONTH),
day = int(tour.STARTDAY),
hour = int(tour.STARTHOUR),
minute = int(tour.STARTMINUTE),
second = int(tour.STARTSECOND),
tzinfo = local_tz
)
# Convert time
start_time_utc = start_time_local.astimezone(utc_tz)
# Create the GPX XML structure
gpx = ET.Element('gpx')
gpx.set('xmlns', 'http://www.topografix.com/GPX/1/1')
gpx.set('version', '1.1')
gpx.set('creator', 'MyTourBook Data Recovery')
gpx.set('xmlns:xsi', 'http://www.w3.org/2001/XMLSchema-instance')
gpx.set('xsi:schemaLocation', 'http://www.topografix.com/GPX/1/1 http://www.topografix.com/GPX/1/1/gpx.xsd')
# Track
trk = ET.SubElement(gpx, 'trk')
ET.SubElement(trk, 'name').text = tour.TOURTITLE
# Track segment
trkseg = ET.SubElement(trk, 'trkseg')
# Add track points
num_points = serie_data['num_points']
for i in range(num_points):
try:
point_time = start_time_utc + timedelta(seconds=int(serie_data['seconds'][i]))
trkpt = ET.SubElement(trkseg, 'trkpt')
trkpt.set('lat', str(serie_data['latitudes'][i]))
trkpt.set('lon', str(serie_data['longitudes'][i]))
ET.SubElement(trkpt, 'ele').text = str(serie_data['altitudes'][i])
ET.SubElement(trkpt, 'time').text = point_time.strftime('%Y-%m-%dT%H:%M:%SZ')
except IndexError as e:
print(f"Error processing point {i}: {e}")
break
# Create GPX filename
gpx_filename = start_time_local.strftime('%Y-%m-%d_%H%M%S') + '_' + tour.TOURTITLE + ".gpx"
# Format the XML nicely
rough_string = ET.tostring(gpx, 'utf-8')
reparsed = minidom.parseString(rough_string)
pretty_xml = reparsed.toprettyxml(indent=" ")
# Save to file
with open(os.path.join(output_dir, gpx_filename), 'w', encoding='utf-8') as f:
f.write(pretty_xml)
os.makedirs(output_dir, exist_ok=True)
tours_df = pd.read_csv(csv_path)
tours_df['TOURTITLE'] = tours_df['TOURTITLE'].fillna('unknown')
print("Starting GPX extraction...")
for tour in tours_df.itertuples():
create_gpx(tour)
End piece of output
1
2
3
4
5
6
7
8
9
10
Processing tour 2012126115419352 (Běžky - Sněžné - NMNM)
Found 3633 data points
Processing tour 2010213112215126 (Běžky - Roženecké paseky - Fryšava)
Found 1076 data points
Processing tour 201177182713058 (Kolo - z práce)
Found 920 data points
Processing tour 2011925125642347 (Kolo - Vlkov - Deblín - Tišnov - Brno)
Found 3271 data points
Processing tour 2012128124715022 (Běžky - Benešov - Kořenec)
Found 1128 data points
And last extracted files:
1
2
3
4
5
2011-09-17_153948_unknown.gpx
2011-09-25_125610_Kolo - Vlkov - Deblín - Tišnov - Brno.gpx
2012-01-15_114217_Běžky - Sněžné - NMNM.gpx
2012-01-26_115448_Běžky - Sněžné - NMNM.gpx
2012-01-28_124708_Běžky - Benešov - Kořenec.gpx
Data recovery tips
- Hex editors/viewers are invaluable - maybe ImHex is not the best, but it was sufficient and free.
- Compare several binary files side by side to isolate static and variable regions.
- Look for known values: number of data points
- Look for increasing trends of integer values and try to interpret them: such as seconds and distance from start
- AI tools are great help for identifying database from directory structure or file names, file magic numbers and so on, and they significantly accelerate coding process (if context is isolated, easy to decsribe and the goal is clear)
- Preferably backup your data in timeless formats: GPX files, EXIF-tagged photos
Related work (Thumbnails from GPX files)
Once I created script that downloads map tiles and plots GPX files as image overlay, available on my github. This was once quite useful tool, but now it’s a bit outdated. Mapy.cz mapy.com changed their internals, OpenStreetMaps now require API key to download tiles without fingerprints and so on.

Closing Thoughts
The workflow blended old-school hex inspection, modern Python libraries, and AI-assisted scripting.
Limit of this software is that it has some start time inaccuracies in order of minutes, I’m not entirely sure it handles daylight saving time properly, there’s certainly one hour offset for Bulgaria, but I’m perfecly happy with the result and it was quite satifying project.
Data from old Garmin Vista HCx GPS are way noisier than data from Garmin Forerunner 255S smartwatch, despite device was chunky and lasted roughly 20 hours using pair of 2000mAh NiMH batteries. But this is not problem of this script.
I guess the best way to keep the data is to import them to Strava. Also from Garmin Connect via autosync. While both Garmin Connect and Strava offer downloading of all cloud stored data, Strava has data in CSV files and it includes photos and activities - as original GPX/FIT/TCX files compressed by gzip. Garmin, on the other hand has data as JSON files with variable fields and then few ZIP files with tens of thousands of FIT files containing who-knows-what. I assume mix of activities, sleep, heart rate, steps, …
Now it’s spring, I suggest exploring nature outside rather that data recovery.
 Valley of Oslava river, 2018-04-19, 49.1364708N, 16.2467481E
Valley of Oslava river, 2018-04-19, 49.1364708N, 16.2467481E