ENG | One Month of Using Claude code
Three side projects, one month, honest results. Where AI genuinely helped, where it fell apart, and what it quietly took away.

I’ve been using Claude code for a month now, on side projects and at work. Here’s how it went.
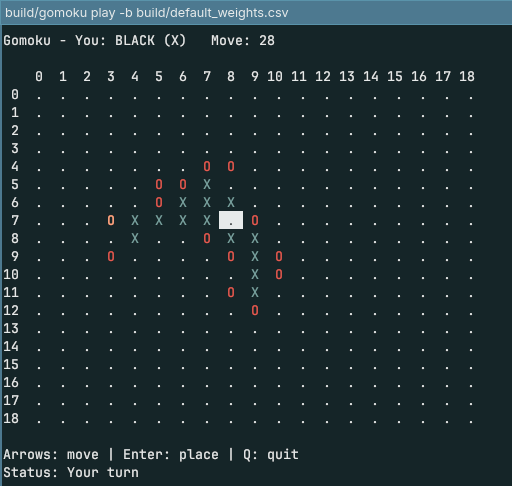
Gomoku
First project: Gomoku, the five-in-a-row game. Server, two clients, move validation, replay saving. I wanted to see if two bots could actually play each other.
It generated everything. It looked fine. But nearly every game on a 19×19 board ended in a draw or a quick win — something was clearly off. I added an ncurses client to watch the bots play. They defended reasonably well but never took initiative, even when the win was sitting right there.
I discussed it with Claude, tweaked things, got slightly better defense. Still draws. The code was unreadable — some position evaluation, some thread evaluation, mysteriously combined. After a few hours I asked DeepSeek to analyze it. Its diagnosis: the bot wasn’t trying to win, it was trying to maximize the number of sequences. A completely different game. I told Claude. It acknowledged the problem. Neither of us could fix it. I gave up.
Out of curiosity I asked if it could build a graphical interface using SDL3 and ImGui. It could. So technically it could have been a web game. That was the most useful thing to come out of the project.
Modplayer
MOD files are a retro audio format from the Amiga and early PC era — basically a header, a list of patterns (a timed table of notes, instruments, and effects), and a list of samples with optional loops. I had written a parser a year earlier and never continued. The next steps were clear but tedious: resample instruments based on output frequency and note, mix channels, implement the timing, handle loops and per-channel state, then implement effects — one by one, for an unknown number of evenings. I kept putting it off.
I asked Claude Code to extract instruments to WAV files. Easy, done. Then: parse patterns, resample based on note, mix, handle timing. I got a working player in maybe 400 lines of C++ — about 40% was my existing parser, 10% audio library glue. Then I added effects, one pass at a time. Then I wanted to analyze my MOD collection for the most-used effects — which tripped it up on an older 15-instrument format — but eventually I had full effect support, handling for several types of corrupted files, all in around 800 lines.
I asked it to rewrite in Rust, add multichannel support, a low-pass filter, linear interpolation. The goal was eventually running on a Raspberry Pi Pico.
Total time: maybe five hours of actual work. It was genuinely good. A few MODs sound slightly off — random ticks, something slightly wrong with a loop — but only in two files out of a large collection.
Then I asked it to add S3M support, a more capable format. The Rust codebase was around 1500 lines at that point. It read the documentation, timed out mid-session but said it had a clear picture, read through the code, made a plan. The plan looked reasonable.
I let it implement. It nearly burned a five-hour token window. The code probably doubled. It compiled. I played the first S3M file and got mostly low-frequency noise.
I asked if it was handling endianness correctly. It said it hadn’t handled 16-bit samples. Which it had explicitly noted as a difference before writing the plan. I asked it to fix that. Now it sounded like noise with hints of melody. I looked at the code.
Some effects had been renumbered to match MOD effect IDs and routed into the MOD player. The instrument sampling frequency — which in S3M differs by several octaves from MOD — had been converted into MOD’s autotune parameter, a 4-bit value covering -8/16 to +7/16 of a semitone. It overflowed several times over. Instead of writing new code for a genuinely different format, it had reused existing code while silently discarding every assumption that made that code work.
There was no fixing this. The code had outgrown its architecture, and AI-assisted refactoring at 3000 lines was not going to happen. I dropped the S3M work. The original player was a success. Adding more formats would be nice, but I don’t need it — and as a learning experience it was nearly worthless. I could tell you the MOD file structure. I couldn’t tell you how half the effects actually work.
Panorama processing pipeline
This one worked well, and I think it’s the clearest example of what AI is actually good for.
The project was a prototype for image stitching — a grid of microscope images that needed to be aligned, globally optimized, and assembled into a pyramidal TIFF for fast zoomed viewing. Five separate tools, each focused, each with a clear input/output contract.
Metadata extraction, pairwise alignment, global optimization with Eigen, tile builder, pyramid builder with multi-resolution output. Each tool was 200–500 lines in Python or C++, using OpenCV, Eigen, nlohmann::json, libtiff. Global optimization — the step I would have found hardest alone — Claude handled without issue once I described the constraint (shifts around any 2×2 image loop should sum to zero).
Part of the work involved reverse-engineering proprietary TIFF tags and OME-TIFF records from third-party files. Part of it was repeatedly reminding Claude that memory is limited and fixing inefficient code. But each tool had a clear boundary, and problems stayed contained.
Where it broke down: when I tried to build a GUI tool using SDL3 and ImGui, it duplicated all the command-line tool logic instead of extracting a shared library. The tools themselves were a mess — application-layer concerns (argument parsing) tangled with logic. When I asked it to refactor, one tool at a time, it removed about 1700 lines and the result was clean. But I had to ask, and it had to be guided.
The viewer was slow. I gave it a resource cache to use. It got ten times worse — it was calling the cache once per pixel. I asked it to draw entire tiles at once. Suddenly 60fps. The fix was obvious in retrospect, but it would never have found it on its own.
Where this leaves things
There’s a pattern I kept running into: progress is fast until it isn’t, and when it stops, it stops hard. The modplayer was five hours of real productivity. Five hours of refinment. The S3M extension was a wall. The panorama tools were smooth and separable right up until they needed to share state.
AI works well on greenfield tasks with clear scope, especially when each step can be verified independently — visually, or with a unit test. It works well with commonly used libraries. It’s good at algorithmic steps that are well-represented in public code. It doesn’t work well when code grows past a certain size, when architecture starts to matter, or when a new feature has implicit assumptions that conflict with old ones.
Refactoring is the most surprising failure. Not because AI can’t restructure code — it can — but because it has no incentive. It sees a minimal working solution and adds features on top. Cleanup happens only when explicitly asked, and even then it tends to miss the point.
The flow is real and genuinely addictive — things get built fast, there’s always something to explore or fix. But after a month it starts to feel less like programming and more like backseat driving. You’re supervising, reviewing, redirecting. The satisfying parts — the slow grind where you actually understand something — get skipped. You don’t need to understand the problem or code deeply until suddenly you do, and by then wrong decisions start to surface.
Learning stops being rewarding and becomes damage control. And architecture — the thing that matters most as a project grows — is exactly where AI is weakest. It builds what works now and hauls technical debt into every new feature.
TL;DR
Where AI excels
- Greenfield projects with no dependencies on existing code
- Tasks separable into focused steps with clear, verifiable output
- Problems already solved many times on GitHub (average textbook solution wins)
- Use of 3rd party libraries, writing CMake files
Where AI fails
- Codebases with internal dependencies and unclear contracts between components
- Refactoring — AI writes minimal working solutions, new features are hacks on top
- Codebases above the 1000–3000 line range, depending on separation
- 3rd party libraries with major version differences
- Application state (loading a new file should reset…)
- Error handling